20 de Abril de 2026
En un artículo para Nieman Lab, Laura Hazard Owen examina cómo distintos modelos de inteligencia artificial utilizan contenido periodístico y qué tan bien, o mal, reconocen a los medios de información que lo producen.
Investigadores canadienses pusieron a prueba las versiones de pago y gratuitas o “económicas” de cuatro modelos de IA, ChatGPT, Claude, Gemini y Grok, con preguntas sobre la actualidad en Canadá, con el objetivo de observar si mencionaban a medios específicos en sus respuestas.
El resultado, según la autora, no resulta especialmente sorprendente, los modelos de IA rara vez citan fuentes periodísticas si no se les solicita explícitamente, y existen diferencias claras entre ellos.
“Estos sistemas han ingerido sistemáticamente el periodismo canadiense. La especificidad de su conocimiento sobre política nacional, asuntos provinciales y cobertura local apunta claramente a fuentes periodísticas canadienses”, escribe en su blog Taylor Owen, titular de la cátedra Beaverbrook en medios, ética y comunicación en la Universidad McGill y coautor del estudio. “Y rara vez te dicen de dónde proviene la información.”
En ese contexto, la autora recuerda que CBC, Globe and Mail, Toronto Star, Postmedia, Metroland Media y The Canadian Press demandaron a OpenAI por infracción de derechos de autor en noviembre de 2024. Se trata del primer caso de este tipo en Canadá y el proceso continúa en curso.
Owen, quien también dirige el Center for Media, Technology, and Democracy, junto con Aengus Bridgman, profesor asistente en McGill, detallan los hallazgos del estudio:
“Probamos cuatro grandes modelos de IA con 2.267 noticias reales de Canadá (en inglés y francés), sin activar la búsqueda web, y encontramos el mismo patrón en todos. Los cuatro modelos mostraron un amplio conocimiento de la actualidad canadiense, consistente con haber incorporado reportes periodísticos del país. Los modelos demostraron al menos conocimiento parcial en el 74% de las respuestas dentro de su ventana de entrenamiento, pero entre esas respuestas, el 92% no ofreció ningún tipo de atribución de fuente.
Cuando activamos la búsqueda web y probamos 140 artículos específicos mediante la API de cada empresa, todos los modelos generaron respuestas que cubrían suficiente del reporteo original como para que muchos usuarios rara vez necesitaran visitar la fuente. Los modelos solían enlazar a sitios de noticias canadienses, con un 52% de respuestas que incluían al menos una URL canadiense, pero solo nombraron una fuente canadiense en el texto de la respuesta el 28% de las veces. Los enlaces ofrecen una vía de regreso a la fuente, pero quienes leen la respuesta rara vez ven una indicación de qué medio produjo el contenido.”
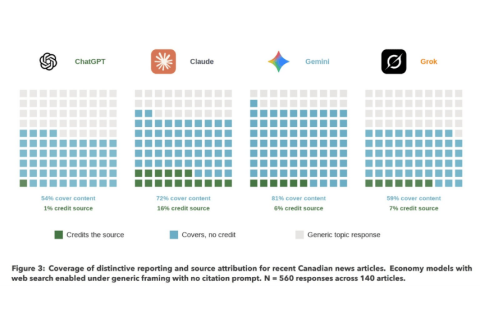
Con la búsqueda web activada, el gráfico incluido en el estudio “muestra la experiencia por defecto del usuario, qué ocurre cuando alguien hace una pregunta general sin solicitar citas. Así es como la mayoría usa los modelos de IA, ‘Cuéntame sobre X’, no ‘¿Qué reportó el Toronto Star sobre X?’”.
Los autores explican:
“Los cuadrados azules muestran con qué frecuencia el resultado cubre suficiente del reporteo distintivo del artículo, eventos específicos, personas mencionadas, hallazgos clave, como para que un lector pueda captar la idea general sin visitar el sitio de noticias. No son reproducciones completas, son resúmenes parciales y paráfrasis que incluyen parte del contenido distintivo del artículo original, aunque a veces contienen errores u omisiones… Evaluamos cada respuesta frente al artículo fuente para determinar si cubría su reporteo distintivo, no solo el tema general. Los cuadrados verdes muestran con qué frecuencia el modelo acredita la fuente nombrando al medio en el texto de la respuesta o mediante citas estructuradas legibles por máquina.
Las tasas de cobertura son altas, pero las de atribución no. Gemini y Claude cubrieron reporteo distintivo en el 81% y el 72% de las respuestas, respectivamente, pero Gemini solo acreditó la fuente el 6% de las veces. Grok cubrió reporteo distintivo en el 59% de las respuestas, citando la fuente en apenas el 7%. ChatGPT, uno de los modelos más utilizados, cubrió contenido distintivo en el 54% de las respuestas, pero casi nunca acreditó a la redacción de origen. Incluso cuando los modelos no cubren el reporteo distintivo, siguen ofreciendo una respuesta temática que puede reducir la motivación del usuario para visitar la fuente.”
De acuerdo con el análisis, ChatGPT es particularmente poco propenso a atribuir fuentes cuando no se le solicita, apenas lo hace en el 1% de los casos de la muestra, frente al 16% de Claude.
Todos los modelos mejoran de forma significativa cuando se les pide explícitamente que incluyan citas, algo que, como sugiere la autora, la mayoría de los usuarios no suele hacer.
“En las condiciones más favorables, nombrar directamente al medio y pedir explícitamente citas, la atribución mejora sustancialmente en todos los modelos. Los cuatro nombraron al medio en la mayoría de las respuestas, Claude (97%), Gemini (95%), ChatGPT (86%) y Grok (74%). Las tasas de enlaces también fueron altas, Grok (91%), Gemini (69%), Claude (64%) y ChatGPT (59%). La atribución significativa es técnicamente posible. La brecha entre la experiencia por defecto y el mejor escenario posible es un hallazgo central, la mayoría de los usuarios nunca nombrará un medio ni pedirá citas, por lo que los resultados en condiciones generales reflejan la experiencia que moldea el mercado del periodismo.”
Según los investigadores, cuando los modelos de IA sí citan fuentes, tienden a privilegiar aquellas que ya son conocidas por el público. Los medios con muro de pago y los regionales más pequeños aparecen con menor frecuencia, incluso cuando producen reportajes originales.
Del estudio:
“Entre los medios en inglés, CBC, CTV y Global News, todos de acceso gratuito, concentran la mayor visibilidad en IA en ambas categorías. Globe and Mail tiene un desempeño relativamente bueno, pero Toronto Star y Financial Post aparecen de forma marginal pese a ser redacciones relevantes. Los periódicos regionales de Postmedia en Calgary, Edmonton, Ottawa y Vancouver están prácticamente ausentes. Entre los medios en francés, Radio-Canada y La Presse dominan, con Le Devoir en un lejano tercer lugar. Journal de Montréal, uno de los diarios más leídos de Quebec, recibió solo 48 menciones en total entre todos los modelos.”
El periodismo en francés queda, en palabras de los investigadores, “doblemente en desventaja”. “Su contenido se incorpora a los datos de entrenamiento de los modelos, pero los medios que lo producen casi nunca son reconocidos.”
La autora también consultó a los responsables del estudio sobre cuál modelo se acerca más a hacer “lo correcto” desde una perspectiva periodística. Aengus Bridgman ofreció una respuesta que refleja la complejidad del panorama. Cabe aclarar que el “cutoff” de un modelo es la fecha hasta la cual ha sido entrenado, las historias “pre-cutoff” pertenecen a ese periodo y las “post-cutoff” son posteriores.
Escribió:
“Es una pregunta realmente difícil porque cada modelo se comporta de forma distinta:
- Claude cita medios canadienses con mayor frecuencia en la primera prueba (61% frente al 8% de ChatGPT y el 3% de Gemini), y cuando no sabe algo, lo dice en lugar de inventarlo. Solo alrededor del 37% de sus respuestas en la versión económica abordaron sustancialmente historias pre-cutoff, pero eso se debe a que se niega a adivinar. La contrapartida es que aun así reproduce contenido con muro de pago a tasas altas (68%) cuando tiene acceso web.
- ChatGPT tiene la mejor interfaz para mostrar noticias recientes (citas en línea, enlaces clicables). Pero su modelo económico es el que más “alucina” (el 87% de sus respuestas post-cutoff generaron respuestas seguras sobre eventos que no podía conocer), y el 88% de esas eran inexactas. Nombra fuentes en el 54% de las respuestas de la segunda prueba, lo cual suena bien hasta notar que también reproduce el reporteo lo suficiente como para sustituir el artículo original el 54% de las veces.
- Gemini es el más ágil y cubre más reporteo distintivo con acceso web (81%), pero casi nunca nombra la fuente canadiense en el texto (2–8%). Es el más eficaz para reemplazar la necesidad de visitar la fuente mientras oculta de dónde proviene la información.
- Grok destaca al identificar medios canadienses solo a partir de sus datos de entrenamiento, sin búsqueda web. Pero también “alucina” agresivamente en historias post-cutoff (el 89% abordó temas que no debería conocer, y el 84% fue inexacto).
Lo que más le sorprendió, fue la complejidad del fenómeno y la diversidad de enfoques adoptados por las empresas. Cada compañía toma decisiones de diseño que generan comportamientos distintos, más o menos responsables, y diferentes niveles de transferencia de valor hacia los medios de información, ya sea a través de referencias a la fuente o del tratamiento de los muros de pago. Estas diferencias, concluye, evidencian una autorregulación aún limitada e incompleta en este ámbito."
El AI News Audit fue publicado por el Center for Media, Technology and Democracy de la Universidad McGill. El informe completo, que incluye recomendaciones de política pública en Canadá sobre inteligencia artificial, está disponible AQUÍ.
Otras noticias

Del headcount al ecosistema: el nuevo enfoque del talento en medios

Una reforma a la publicidad digital, clave para la sostenibilidad del periodismo

Estrategia y suscripción: el ejemplo de los medios nórdicos